如果你关注 Node.js 社区,那么你一定记得 Node.js v12 一个非常重磅的功能就是,内核的 HTTP Parser 默认使用 llhttp,取代了老旧的 http-parser,性能提升了 156%。
但知其然也要知其所以然,llhttp 是如何做到这一点的呢?
http-parser 的过去和现状
之前 Node.js 使用的 http-parser 是 Node.js 中最古老的几个依赖之一,始于 2009 年(也是 Node.js 的元年)。在那个年代,Node.js 的定位是一个后端开发平台,其目标之一就是能快速搭建异步的 HTTP Server,所以 http-parser 是最核心的模块之一,也影响了 Node.js 内部很多代码、模块的设计。它的设计上参考了 Ruby 的 mongrel,也同样使用了小部分来自 Nginx 的代码,还有一部分代码是 RY 自己写的。
http-parser 其实是有很多优点的,比如它的性能足够好;兼容了很多“非标准”的 HTTP 客户端;积累了足够完善的测试用例,这些优点让它经受住了时代的考验,毕竟对于一个技术项目而言,十多年已经是一个非常久的时间了。
但是它也有缺点,随着时间的推移,无数的迭代,它的代码变得越来越僵硬(“rigid”),很难对它进行大的改动,或者做很大的优化,这也导致它难以维护,任何代码的变更都可能会引入 bug 或者安全问题。
另外,http-parser 是纯 C 实现的,而 Node.js 的受众主要是 JavaScript 开发者,这些开发者中大部分人都不是 C 语言的专家,这也给维护带来了困难。
所以,Node.js 需要一个新的 HTTP Parser,这也就是 llhttp 的来源,它起码需要以下几种特性:
- 性能要好于 http-parser,或者至少不能更差;
- 最好使用 JS/TS 实现,便于社区维护;
- 对外接口尽量保持一致,便于无缝升级。
HTTP Parser 是什么?它在做什么?
我们在这里不过多深入 HTTP 的细节,只是做一些简单的介绍。
HTTP 是一种应用层的文本协议,建立在 TCP 之上,由三个部分组成:起始行(start-line)、头部(headers)、传输体(body)。
比如下面就是一个完整的 HTTP 请求的例子:
POST /user/starkwang HTTP/1.1 <--- 起始行
Host: localhost:8080 <--- 头部开始
Connection: keep-alive
User-Agent: Mozilla/5.0 (Macintosh; ...
Content-Type: application/json; charset=utf-8 <--- 头部结束
{"text": "这里是Body!!"} <--- 传输体当然这只是理论,实际上收发、处理一个 HTTP 请求并没有那么简单,比如对于 Node.js 的 Runtime 层面而言,它收到的来自传输层 TCP 的数据实际上是几串离散的数据,比如:
POST /user/starkw
------------我是分割线---------------
ang HTTP/1.1
Host: localho
------------我是分割线---------------
st:8080
Connection: keep-alive
User-Agent: Mozilla/5.0 (Macintosh; ...
Content-Type: appli
------------我是分割线---------------
cation/json; charset=utf-8
{"text": "这
------------我是分割线---------------
里是Body!!"}HTTP Parser 的工作之一就是把这几串数据接收并且解析完毕(如果遇到不符预期的输入则报错),并将解析结果转换成文本和 JavaScript 侧可以处理的对象。下面是一个便于理解的例子:
{
method: 'GET'
headers: {
'Host': 'localhost:8080',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Macintosh; ...',
'Content-Type': 'application/json; charset=utf-8'
},
body: '{"text": "这里是Body!!"}'
}(实际上,Node.js 里面是以 IncomingMessage 和 ServerResponse 的形式表示的)
llhttp 是怎么实现的?
如果你学过或者接触过一点编译原理的话,很容易就想到 HTTP Parser 本质上是一个有限状态机,我们接收并解析 start-line、headers、body 时,只是在这个状态机内部进行转换而已。
HTTP 状态机
假设我们正在接收一个 HTTP 请求,我们收到了 HTTP 请求的第一个字符,发现这个字符是 G,那么我们接下来应该期望收到一个 start-line 的方法名 GET。
但如果第二个字符收到了 A,那么就应该立刻报错,因为没有任何 HTTP 方法是以 GA 开头,根据这个步骤,我们就得到了一个很简单的状态机:
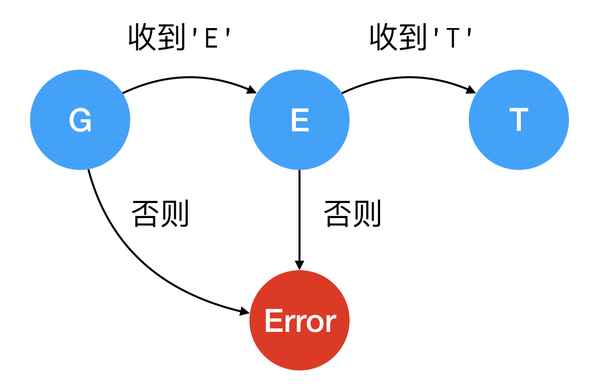
顺着相同的思路,将这个状态机进一步扩展,我们就可以解析完整的 HTTP 请求了:
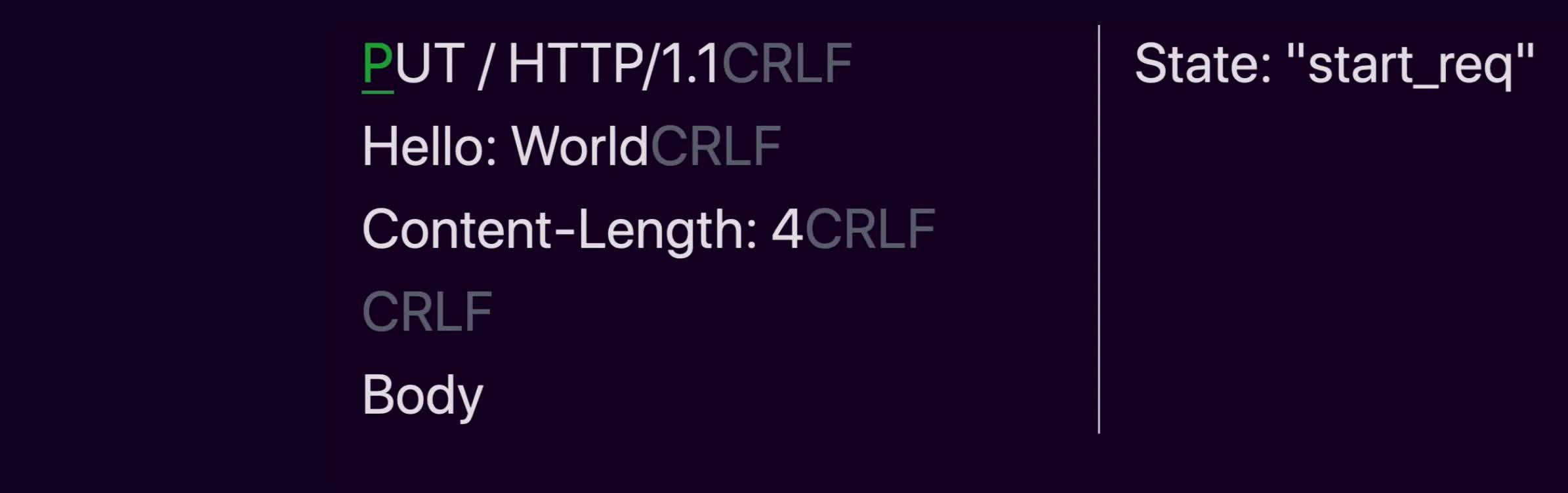
下面是实际上的 llhttp 内部的状态机(大图请看这里):
{kind=link}

如何优雅地实现状态机
理论有了,那么我们接下来的问题就是如何用代码优雅地实现一个有限状态机?
比如我们可以用一个 switch 来解决:
const state = 0
function excute() {
swtich(state) {
case 0:
// do something...
state = 3
case 1:
// do something...
state = 0
// ...
}
}
while(true) {
excute()
}可是 switch 的问题在于:
- 大型的状态机会存在成百上千种状态,把这么多状态放在一个巨大的 switch 中,是很反人类的事情;
- 对于解析文本协议而言,有很多重复的动作,比如“连续匹配 POST 这四个字符”,这种“连续匹配”的行为是可以进一步抽象的,而不是写成多个状态;
使用 DSL 描述状态机
为了解决上述问题,llhttp 使用了一种基于 TypeScript 的 DSL(领域特定语言) llparse,用于描述有限状态机。
llparse 支持将描述状态机的 TypeScript 编译为 LLVM Bitcode(这也是为啥叫 llparse 的原因)、或者 C 语言、或者 JavaScript。它起码有以下几种优势:
- 不需要手写大量重复的状态机转换的代码
- 可以输出到多种语言,其中 llhttp 使用的是 C 语言
- 可以在编译期间对状态机进行静态分析和优化,合并冗余的状态
llparse 快速入门
现在关于 llparse 的文档和文章几乎没有,llparse 本身也只有 Fedor Indutny 一个维护者,所以想要理解 llparse 的 API 是有一定难度的。
简单介绍
llparse 使用 TypeScript 描述一个专用于匹配文本的状态机,所以它的一切 API 都是为描述一个这样的状态机而设计的。
在 llparse 中,所有状态都是一个节点(node):
// 创建一个状态 foo
const foo = p.node('foo')我们可以通过各种 API 来描述节点之间的转换关系,或者各种状态机的动作,这些 API 包括但不仅限于:
- match
- otherwise
- peek
- skipTo
- select
- invoke
- code
- span
下面分别介绍这些 API。
match 与 otherwise
.match() 表示在当前状态时,尝试匹配一串连续输入。
下面这段代码尝试连续匹配 'hello',如果匹配成功,那么跳转到下一个节点 nextNode;否则调用 .otherwise() 跳转到 onMismatch:
const foo = p.node('foo')
foo.match('hello', nextNode).otherwise(onMismatch)peek 与 skipTo
.peek() 表示提前查看下一个字符( peek 有“偷窥”的意思),但是不消费它。
下面的代码表示,当下一个字符是 '\n' 的时候,跳转到 nextNode,否则使用 .skipTo() 消费一个字符,跳回到 foo 重新循环。
foo.peek('\n', nextNode).skipTo(foo)注意,.skipTo() 和 .otherwise() 的区别在于, 前者会消费一个字符,而后者不会。
所以如果我们使用 .otherwise() 替换上面的 .skipTo(),就会收到一个错误,告诉我们检测到了死循环:
foo.peek('\n', nextNode).otherwise(foo)
//=> Error: Detected loop in "foo" through chain "foo"select
.select() 用于匹配一串文本,并且把匹配到的文本映射到某个值上,然后把这个值传入下一个状态。
foo.select({
'GET': 0,
'POST': 1
}, next)比如,在接收 HTTP 请求的时候,根据规范,开头的前几个字符必然是 HTTP 方法名,那么我们可以这样接收:
const method = p.node('method')
method
.select({
'HEAD': 0, 'GET': 1, 'POST': 2, 'PUT': 3,
'DELETE': 4, 'OPTIONS': 5, 'CONNECT': 6,
'TRACE': 7, 'PATCH': 8
}, onMethod)
.otherwise(p.error(5, 'Expected method'))invoke 与 code
任何有意义的状态机最终肯定是要对外部产生输出的,比如调用外部函数,或者存储一些状态到外部的属性上面,.invoke() 和 .code 就是为此而设计的。
.invoke() 调用一个外部函数,并且根据外部函数的返回值,映射到不同的下个状态,如果没有映射,那么跳入错误状态中。
.code.match() 返回一个外部函数的引用。
const onMatch = p.invoke(
p.code.match("bar"),
{
1: nextNode1,
2: nextNode2
},
p.error(1, "bar error")
)我们这里调用了外部函数 bar,并且根据返回值确定下一个状态 nextNode1 或 nextNode2,如果返回值是预期外的,那么跳入错误状态。
span
.span() 表示在一段时间内,为输入的每个字符产生一次回调。
const callback = p.code.span('onByte')
const onByte = p.span(callback)
node.match('start', onByte.start(nextNode))
nextNode.match('end', onByte.end(nextNextNode))上面我们尝试匹配 'start',如果匹配成功,那么跳入 nextNode,并且开始为每个匹配到的字符触发 onByte() 回调,直到匹配完毕 'end',我们结束触发回调,并且跳入 nextNextNode。
使用 llparse 构建简单的 Parser
单纯地讲 API 是很枯燥的,我们来实战试一试,我们尝试构建一个匹配 'hello' 的 Parser。
首先我们创建一个 start 状态节点,代表起始状态:
import { LLParse } from "llparse"
const p = new LLParse("myfsm")
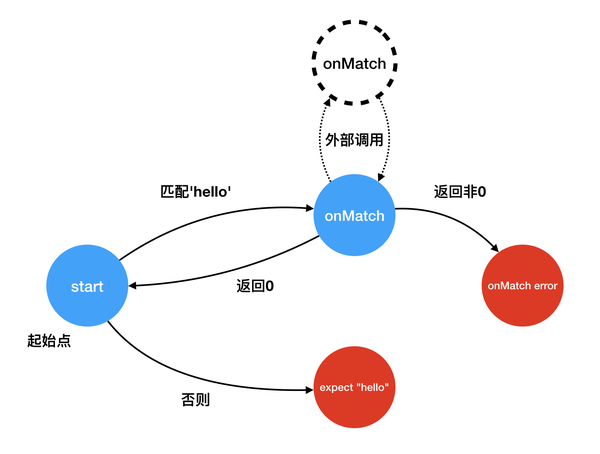
const start = p.node('start')我们可以尝试使用 .match() 连续匹配一串输入,如果匹配成功,那么跳转到下一个状态节点 onMatch;否则跳转到 onMismatch:
start
.match('hello', onMatch)
.otherwise(onMismatch)然后 onMatch 中,我们使用 .invoke() 产生一个外部调用,调用的是注入的外部方法 onMatch,如果它返回 0,那么就跳转回到 start 状态,否则报错
const onMatch = p.invoke(
p.code.match("onMatch"),
{
0: start
},
p.error(1, "onMatch error")
)于是我们就得到了这样一个简单的状态机:
下面是完整的代码:
import { LLParse } from "llparse"
import { writeFileSync } from "fs"
const p = new LLParse("myfsm")
// 创建状态节点 start
const start = p.node("start")
// 创建调用节点 onMatch
const onMatch = p.invoke(
p.code.match("onMatch"),
{
0: start
},
p.error(1, "onMatch error")
)
// start 状态匹配到 hello 之后,进入 onMatch节点
// 否则输出 expect "hello"
start.match("hello", onMatch).otherwise(p.error(1, 'expect "hello"'))
// 编译状态机
// 状态机从 start 开始
const artifacts = p.build(start)
// 输出编译结果
writeFileSync("./output.js", artifacts.js)
writeFileSync("./output.c", artifacts.c)运行上述代码,我们就得到了状态机的编译结果 output.js。
然后我们可以试用一下编译出来的状态机代码:
import makeParser from './output'
// 传入外部函数,创建 Parser
const Parser = makeParser({
onMatch: (...args) => {
console.log('match!')
return 0
}
})
const parser = new Parser()
parser.execute(Buffer.from('hel'))
//=> 0,代表没有报错
parser.execute(Buffer.from('lo'))
//=> 打印 'match!',同样返回 0注意,我们这里即使把 'hello' 分为两段输入状态机,状态机依然可以成功匹配。
但如果我们输入了预期外的字符串,那么就会让状态机进入错误状态:
const parser = new Parser()
parser.execute(Buffer.from('starkwang'))
//=> 返回 1,代表错误状态llhttp 是如何使用 llparse 的?
解析 HTTP 协议,和我们上面构建的这个简单的 Parser 其实原理上是一样的(只是前者复杂得多而已),比如下面就是一段解析 HTTP 起始行(start-line)的状态机代码(来自 llparse 的 README):
import { LLParse } from 'llparse';
const p = new LLParse('http_parser');
const method = p.node('method');
const beforeUrl = p.node('before_url');
const urlSpan = p.span(p.code.span('on_url'));
const url = p.node('url');
const http = p.node('http');
// Add custom uint8_t property to the state
p.property('i8', 'method');
// Store method inside a custom property
const onMethod = p.invoke(p.code.store('method'), beforeUrl);
// Invoke custom C function
const complete = p.invoke(p.code.match('on_complete'), {
// Restart
0: method
}, p.error(4, '`on_complete` error'));
method
.select({
'HEAD': 0, 'GET': 1, 'POST': 2, 'PUT': 3,
'DELETE': 4, 'OPTIONS': 5, 'CONNECT': 6,
'TRACE': 7, 'PATCH': 8
}, onMethod)
.otherwise(p.error(5, 'Expected method'));
beforeUrl
.match(' ', beforeUrl)
.otherwise(urlSpan.start(url));
url
.peek(' ', urlSpan.end(http))
.skipTo(url);
http
.match(' HTTP/1.1\r\n\r\n', complete)
.otherwise(p.error(6, 'Expected HTTP/1.1 and two newlines'));
const artifacts = p.build(method);
console.log('----- BITCODE -----');
console.log(artifacts.bitcode); // buffer
console.log('----- BITCODE END -----');
console.log('----- HEADER -----');
console.log(artifacts.header);
console.log('----- HEADER END -----');当然你也可以直接去读 llhttp 的核心状态机代码:llhttp/http.ts
为什么 llhttp 会比 http-parser 更快?
- llparse 在编译 DSL 时有静态分析的过程,这期间会做一些状态机的优化,例如状态合并。比如匹配 ‘POST’、‘PUT’、‘PATCH’ 的时候,就会合并第一个 ‘P’ 字符的状态,而不是生成三个独立的中间态;
- http-parser 为了 C 代码的可读性和 DRY,存在很多抽象,这些抽象其实是一种 trade-off,是存在性能损失的。而 llparse 完全不需要考虑编译结果的可读性,所以甚至可以在编译出的 C 代码里大量使用 goto 替代条件判断,这里也间接提升了性能。
总结
- llhttp 使用有限状态机解析 HTTP 协议,保证性能的同时也提升了代码的可维护性;
- 为了使状态机的代码简洁明了,llparse 被设计了出来,这是一门基于 TypeScript 的用于描述解析文本的状态机 DSL;
- llparse 提供了一系列 API 对状态机的行为进行抽象,并且可以把状态机编译到 LLVM Bitcode、C、JavaScript。